|
Chenyang Lei is an assistant professor at Centre for Artificial Intelligence and Robotics (CAIR), Chinese Academy of Sciences. He is also a visiting scholar at Princeton University and working with Felix Heide. He received his Ph.D. in computer science from the Hong Kong University of Science and Technology (HKUST), supervised by Qifeng Chen. He was a research intern at MSRA, Nvidia, and Sensetime. He obtained his Bachelor's degree at Zhejiang University in 2018. I am currently in the job market. |

|
|
|
|
I am interested in exploring system designs of visual computing pipelines, from advanced sensing technologies to more capable artificial intelligence. My current research topics include:
|
|
|
|
Chenyang Lei, Liyi Chen, Jun Cen, Xiao Chen, Zhen Lei, Felix Heide, Qifeng Chen, Zhaoxiang Zhang arxiv, 2024 paper / project website / code This work presents a simple and effective framework SimCMF to study an open problem: the transferability from vision foundation models trained on natural RGB images to other image modalities of different physical properties (e.g., polarization). |
 
|
Zian Qian, Zhili Chen, Mengxi Sun, Zhaoxiang Zhang, Qifeng Chen, Chenyang Lei In submission, 2024 paper / project website / code We propose the Vision-Language-Camera Model (VLC), which introduces the vision-language model to camera manual mode and offers guidance on how to adjust camera parameters tailored to the user's specific needs. |
 
|
Xiao Chen, Xudong Jiang, Yunkang Tao, Zhen Lei, Qing Li, Chenyang Lei†, Zhaoxiang Zhang† AAAI, 2024 paper / project website / code This paper presents a novel framework for Flexible Interactive Reflection Removal with various forms of guidance, where users can provide sparse visual guidance (e.g., points, boxes, or strokes) or text descriptions for better reflection removal. |
|
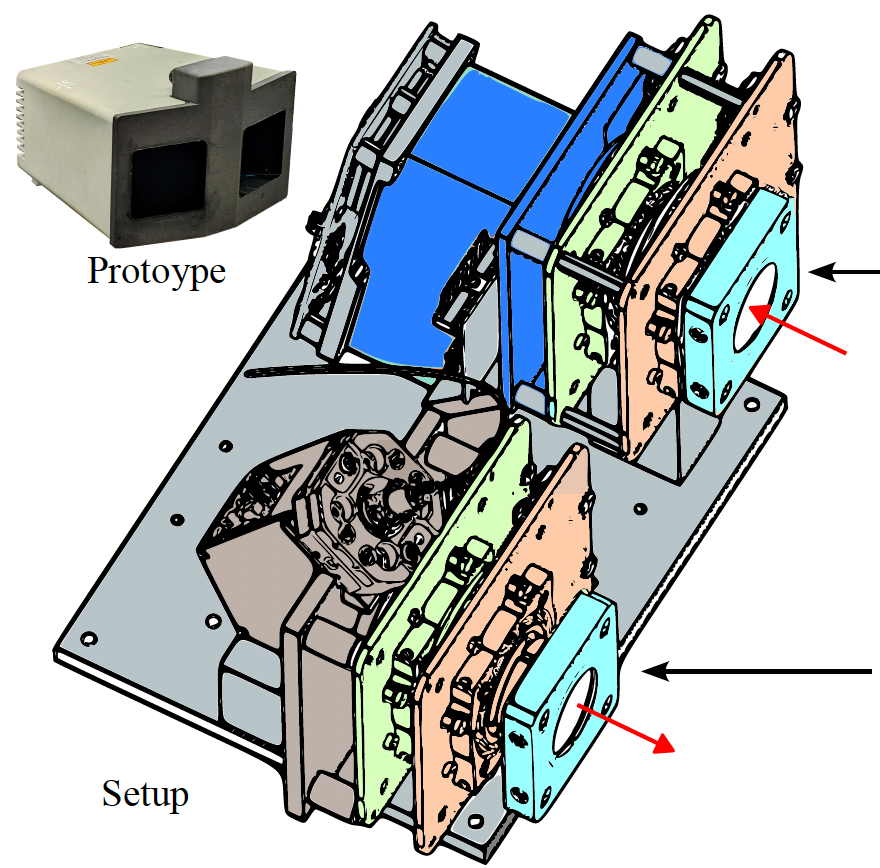
Dominik Scheuble*, Chenyang Lei*, Mario Bijelic, Seung-Hwan Baek, Felix Heide CVPR, 2024 paper / project website / code In this work, we introduce a novel long-range polarization wavefront lidar sensor (PolLidar) that modulates the polarization of the emitted and received light. |
 
|
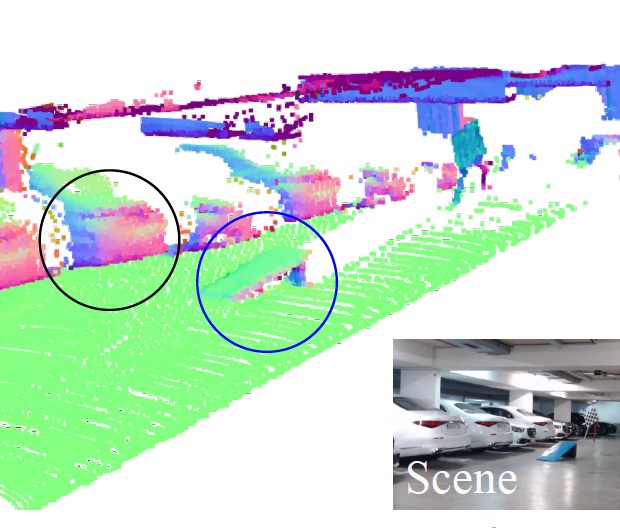
Kei IKEMURA*, Yiming Huang*, Felix Heide, Zhaoxiang Zhang, Qifeng Chen, Chenyang Lei† CVPR, 2024 paper / project website / code In this work, we present a general framework that leverages polarization imaging to improve inaccurate depth measurements from various depth sensors. |
 
|
Xiaoyan Cong, Yue Wu, Qifeng Chen, Chenyang Lei† CVPR, 2024 paper / project website / code We present a novel approach to automatic image colorization by imitating the imagination process of human experts. |
 
|
Ilya Chugunov, David Shustin, Ruyu Yan, Chenyang Lei, Felix Heide CVPR, 2024 paper / project website / code In this work, we use burst image stacks for layer separation. We represent a burst of images with a two-layer alpha-composited image plus flow model constructed with neural spline fields networks trained to map input coordinates to spline control points. |

|
Praneeth Chakravarthula, Jipeng Sun, Xiao Li, Chenyang Lei, Gene Chou, Mario Bijelic, Johannes Froech, Arka Majumdar, Felix Heide SIGGRAPH Asia, 2023 paper / project website We propose a thin nanophotonic imager that employs a learned array of metalenses to capture a scene in-the-wild. |
|
Huimin Wu*, Chenyang Lei*, Xiao Sun, Peng-Shuai Wang, Qifeng Chen, Kwang-Ting Cheng, Stephen Lin, Zhirong Wu ICCV, 2023 arxiv / project website / code A modality-agnostic augmentation for constrative learning, which can be applied to image, audio, pointclouds, sensors and other modalities. |

|
Chenyang Qi, Xiaodong Cun, Yong Zhang, Chenyang Lei, Xintao Wang, Ying Shan, Qifeng Chen ICCV, 2023 arxiv / project website / code A zero-shot text-driven video style and local attribute editing model. |

|
Chenyang Lei, Xuanchi Ren, Zhaoxiang Zhang, Qifeng Chen CVPR, 2023 arxiv / project website / code We present a general postprocessing framework that can remove different types of flicker from various videos, including videos from video capturing, processing, and generation. |
 
|
Jiaxin Xie*, Hao Ouyang*, Jingtan Piao, Chenyang Lei , Qifeng Chen CVPR, 2023 arxiv / project website / code We present a high-fidelity 3D generative adversarial network (GAN) inversion framework that can synthesize photo-realistic novel views while preserving specific details of the input image. |
 
|
Chenyang Lei, Yazhou Xing, Hao Ouyang, Qifeng Chen TPAMI , 2022 code We extend the deep video prior (NeurIPS 2020) to video propagation. We also improve the training efficiency for deep video prior. |
 
|
Chenyang Lei*, Chenyang Qi, Jiaxin Xie, Na Fan, Vladlen Koltun , Qifeng Chen CVPR, 2022 arxiv / project website / code We present a new data-driven approach with physics-based priors to scene-level normal estimation from a single polarization image. |
 
|
Chenyang Lei, Qifeng Chen CVPR , 2021 arxiv / code / project website We propose a simple yet effective reflection-free cue for robust reflection removal from a pair of flash and ambient (no-flash) images. The reflection-free cue exploits a flash-only image obtained by subtracting the ambient image from the corresponding flash image in raw data space. The flash-only image is equivalent to an image taken in a dark environment with only a flash on. |
 
|
Hao Ouyang*, Zifan Shi*, Chenyang Lei, Ka Lung Law, Qifeng Chen CVPR , 2021 paper / code We present a controllable camera simulator based on deep neural networks to synthesize raw image data under different camera settings, including exposure time, ISO, and aperture. |
 
|
Chenyang Lei, Yazhou Xing, Qifeng Chen NeurIPS , 2020 arxiv / code / project website Applying image processing algorithms independently to each video frame often leads to temporal inconsistency in the resulted video. To address this issue, we present a novel and general approach for blind temporal video consistency. |
|
Jiaxin Xie, Chenyang Lei, Zhuwen Li, Li Erran Li, Qifeng Chen IROS , 2020 arXiv / code / project website We present an approach with a differentiable flowto-depth layer for video depth estimation. |
 
|
Chenyang Lei, Xuhua Huang, Mengdi Zhang, Qiong Yan, Wenxiu Sun, Qifeng Chen CVPR, 2020 arXiv / code / project website Polarization information and perfect alignment are utilized to remove reflection accurately. |
 
|
Chenyang Lei, Qifeng Chen CVPR, 2019 project page / video / code The first dedicated video colorization method without any user input. |
|
|
|
|
Thank Dr. Jon Barron for sharing the source code of his personal page. |